汽车技术相关笔记
相关概念
CAN & CANoe
CAN(Controller Area Network, 控制器局域网络)是一种用于嵌入式系统的多主机局部网络串行通信协议,广泛应用于汽车、工业自动化、医疗设备等领域。由博世公司在1980年代为汽车应用开发,目的是使车辆内的电子控制单元(ECU)之间能够以高可靠性和低成本进行通信。
- 数据传输速度相对较高,可达到1 Mbit/s。
- 采用差分数据线,抗干扰能力强;
- 多主通信模式,减少单点通信线束成本;
- 具有错误侦听的自我诊断功能,通信可靠信较高。
![picture 2]() 两根线CAN-H、CAN-L,所有的CAN节点连接到上面。每个CAN节点包含CAN收发器、CAN控制器、MCU、MCU应用电路(如控制电机)四大部分。
在发送数据时,CAN控制器把要发送的二进制编码通过CAN_Tx线发送到CAN收发器,然后由收发器把这个普通的逻辑电平信号转化成差分信号,通过差分线CAN_High和CAN_Low输出到CAN总线网络。接收数据过程则相反。采用双线差分信号,用两根信号线的电压差来表示逻辑0和逻辑1的传输方式,可以有效地抑制共模干扰
CAN收发器的作用则是把逻辑信号转换为差分信号。 CAN总线分高速CAN和低速CAN,收发器也分为高速CAN收发器(1Mbps)和低速CAN收发器(125Kbps)。低速CAN也叫Fault Tolerance CAN,指的是即使总线上一根线失效,总线依然可以通信。
两根线CAN-H、CAN-L,所有的CAN节点连接到上面。每个CAN节点包含CAN收发器、CAN控制器、MCU、MCU应用电路(如控制电机)四大部分。
在发送数据时,CAN控制器把要发送的二进制编码通过CAN_Tx线发送到CAN收发器,然后由收发器把这个普通的逻辑电平信号转化成差分信号,通过差分线CAN_High和CAN_Low输出到CAN总线网络。接收数据过程则相反。采用双线差分信号,用两根信号线的电压差来表示逻辑0和逻辑1的传输方式,可以有效地抑制共模干扰
CAN收发器的作用则是把逻辑信号转换为差分信号。 CAN总线分高速CAN和低速CAN,收发器也分为高速CAN收发器(1Mbps)和低速CAN收发器(125Kbps)。低速CAN也叫Fault Tolerance CAN,指的是即使总线上一根线失效,总线依然可以通信。
 两根线CAN-H、CAN-L,所有的CAN节点连接到上面。每个CAN节点包含CAN收发器、CAN控制器、MCU、MCU应用电路(如控制电机)四大部分。
在发送数据时,CAN控制器把要发送的二进制编码通过CAN_Tx线发送到CAN收发器,然后由收发器把这个普通的逻辑电平信号转化成差分信号,通过差分线CAN_High和CAN_Low输出到CAN总线网络。接收数据过程则相反。采用双线差分信号,用两根信号线的电压差来表示逻辑0和逻辑1的传输方式,可以有效地抑制共模干扰
CAN收发器的作用则是把逻辑信号转换为差分信号。 CAN总线分高速CAN和低速CAN,收发器也分为高速CAN收发器(1Mbps)和低速CAN收发器(125Kbps)。低速CAN也叫Fault Tolerance CAN,指的是即使总线上一根线失效,总线依然可以通信。
两根线CAN-H、CAN-L,所有的CAN节点连接到上面。每个CAN节点包含CAN收发器、CAN控制器、MCU、MCU应用电路(如控制电机)四大部分。
在发送数据时,CAN控制器把要发送的二进制编码通过CAN_Tx线发送到CAN收发器,然后由收发器把这个普通的逻辑电平信号转化成差分信号,通过差分线CAN_High和CAN_Low输出到CAN总线网络。接收数据过程则相反。采用双线差分信号,用两根信号线的电压差来表示逻辑0和逻辑1的传输方式,可以有效地抑制共模干扰
CAN收发器的作用则是把逻辑信号转换为差分信号。 CAN总线分高速CAN和低速CAN,收发器也分为高速CAN收发器(1Mbps)和低速CAN收发器(125Kbps)。低速CAN也叫Fault Tolerance CAN,指的是即使总线上一根线失效,总线依然可以通信。CANoe是由德国公司Vector Informatik开发的一款强大的开发、测试和仿真工具,主要用于基于CAN总线的系统开发。它支持从早期设计到最终测试的整个开发过程。
- 仿真与测试:CANoe可以仿真整个CAN网络,帮助开发者在实际硬件出来之前进行开发和调试。此外,它还支持实时测试,可以连接到物理总线,进行实际环境中的测试。
- 分析与诊断:CANoe内置了丰富的分析工具,能够捕捉和分析总线上所有的消息,有助于开发者理解系统行为并排除故障。
- 扩展性:CANoe不仅支持CAN,还支持其他总线协议如LIN、FlexRay、MOST以及Ethernet等。这使得它非常适合用于复杂的多总线系统开发。
- 自动化:CANoe支持脚本编写和自动化测试,可以通过CAPL(CAN Access Programming Language)语言编写复杂的测试和仿真脚本,提高开发效率。
CAN和CANoe通常用于汽车电子系统的开发与测试。典型的应用包括ECU之间的通信测试、网络负载分析、故障诊断以及对系统行为的仿真验证。CANoe的强大功能使得它在汽车行业内非常受欢迎,特别是在复杂的电子系统开发中扮演着重要角色。
GHS
Green Hills Software(GHS)是美国Green Hills软件公司提供的一种具有调试、编译器和闪存编程工具的集成开发环境,是汽车电子行业常用且重要的开发环境之一。它支持的功能包括:AUTOSAR感知、性能分析器、项目构建器、代码覆盖、运行时错误检查、MISRA C符合向导和DoubleCheck™集成式静态代码分析器。
交叉编译工具链是一种能够在一种体系结构(如x86桌面系统)上编译出适用于另一种体系结构(如ARM、PowerPC等嵌入式处理器)的二进制代码的工具集。
GHS工具链主要包括以下几个组件:
- 编译器(Compiler):将高级编程语言(如C/C++)编写的源代码编译为目标嵌入式系统可执行的机器代码。
- 汇编器(Assembler):将汇编语言代码转换为目标处理器的机器码。
- 链接器(Linker):将多个编译或汇编生成的目标文件链接成最终的可执行程序。
- 调试器(Debugger):用于在嵌入式系统上调试程序,帮助开发人员分析和修复代码中的问题。
- 仿真器(Simulator):为没有物理硬件时提供一个虚拟的运行环境,帮助开发人员在PC上进行软件开发和调试。
GHS编译工具链因其高效的代码优化能力以及广泛的硬件支持,在航空航天、汽车、工业控制等高可靠性要求的嵌入式领域中得到了广泛应用。特别是它对实时操作系统(RTOS)的支持以及严格的代码安全性检查,使其成为安全关键型应用开发的首选。
ASPICE
Automotive SPICE(Software Process Improvement and Capability dEtermination) 是由欧洲的主要汽车制造商共同策定的面向汽车行业的流程评估模型, 旨在改善和评估汽车电子控制器的系统和软件开发质量。0. Incomplete process
- Performed process
- Managed process
- Established process
- Predicatable process
- Innovating process
相机标定
一文带你搞懂相机内参外参(Intrinsics & Extrinsics)
相机标定(Camera calibration)原理、步骤
相机标定:求出相机的内、外参数,以及畸变参数。
在图像测量过程以及机器视觉应用中,为确定空间物体表面某点的三维几何位置与其在图像中对应点之间的相互关系,必须建立相机成像的几何模型,这些几何模型参数就是相机参数。
- 由于每个镜头的畸变程度各不相同,通过相机标定可以校正这种镜头畸变矫正畸变,生成矫正后的图像;
- 根据获得的图像重构三维场景。
内参(Intrinsic Parameters)
内参是描述相机内部属性的参数,包括焦距、主点(光学中心)坐标、畸变系数等。内参通常在相机标定时确定,因为它们通常对于特定相机型号是固定的,不随时间变化。一旦相机内参被确定,它们在相机的使用过程中通常是保持不变的。
内参矩阵(相机矩阵),用于描述相机的内部特性
$$
K = \begin{bmatrix}
f_x & 0 & c_x \
0 & f_y & c_y \
0 & 0 & 1
\end{bmatrix}
$$
- f_x, f_y: 焦距(像素单位)
- c_x, c_y: 主点(光学中心)
对于鱼眼相机,鱼眼镜头的成像受到严重的非线性畸变影响,因此需要额外的畸变参数来描述其投影模型。常见的畸变模型包括:
- 多项式模型:
$$
r’ = k_1 r + k_2 r^3 + k_3 r^5 + k_4 r^7
$$
其中, 𝑟 是理想点到中心的径向距离, 𝑟 ′ 是畸变后的位置, 𝑘 1 , 𝑘 2 , 𝑘 3 , 𝑘 4 是畸变系数。 - 等距投影模型(Equidistant Model):
$$
\theta = k_1 r + k_2 r^2 + k_3 r^3 + k_4 r^4
$$
其中 𝜃 是入射光线的角度, 𝑟 是图像上的径向距离。
外参(Extrinsic Parameters)
外参是描述相机在世界坐标系中的位置和姿态的参数,通常包括旋转矩阵和平移向量。外参在不同的相机位置或拍摄时刻可能会发生变化。
描述相机相对于世界坐标系的位置和方向,由旋转矩阵
𝑅 和平移向量 𝑡 组成:
$$
[R | t] =
\begin{bmatrix}
r_{11} & r_{12} & r_{13} & t_x \
r_{21} & r_{22} & r_{23} & t_y \
r_{31} & r_{32} & r_{33} & t_z
\end{bmatrix}
$$
- 𝑅 是 3×3 旋转矩阵,用于表示相机的旋转。
- 𝑡 是 3×1 平移向量,用于表示相机的位置。
摄像机标定过程,可以简单的描述为通过标定板,得到n个对应的世界坐标三维点Xi和对应的图像坐标二维点xi,这些三维点到二维点的转换都可以通过相机内参K ,相机外参 R 和t,以及畸变参数 D ,经过一系列的矩阵变换得到。
相机标定方法有:传统相机标定法、主动视觉相机标定方法、相机自标定法。
常用术语
内参矩阵: Intrinsic Matrix
焦距: Focal Length
主点: Principal Point
径向畸变: Radial Distortion
切向畸变: Tangential Distortion
旋转矩阵: Rotation Matrices
平移向量: Translation Vectors
平均重投影误差: Mean Reprojection Error
重投影误差: Reprojection Errors
重投影点: Reprojected Points

世界坐标系—(外参)—>相机坐标系—(内参)—>像素坐标系
- 世界坐标系就是物体在真实世界中的坐标(参考坐标系,车辆坐标系);
- 相机坐标系以光心为相机坐标系的原点,以平行于图像的x和y方向为Xc轴和Yc轴,Zc轴和光轴平行,Xc,Yc,Zc互相垂直,单位是长度单位。
- 图像物理坐标系以主光轴和图像平面交点为坐标原点,x和y方向如图所示,单位是长度单位。
- 图像像素坐标系以图像的顶点为坐标原点,u和v方向平行于x和y方向,单位是以像素计。
(U,V,W)是世界坐标系,经过刚体变换(如:旋转、平移)后变为了相机坐标系,再次经过透视投影转变为了图像坐标系,最后经仿射变换转换为了像素坐标系(u,v)。转换关系如下(Z是尺度因子):
相机模型
针孔相机模型
相机将三维世界中的坐标点(单位为米)映射到二维图像平面(单位为像素)的过程能够用一个几何模型进行描述,这个几何模型就是所谓的相机模型。模型有很多种,其中一种最简单有效的模型称为针孔模型。它描述了一束光线通过针孔之后,在针孔背面投影成像的关系。同时,由于相机镜头上的透镜的存在,会使得光线投影到成像平面的过程中会产生畸变。
鱼眼相机模型
由于相机镜头上的透镜的存在,会使得光线投影到成像平面的过程中会产生畸变。这一点在鱼眼相机中表现尤其明显,如图。
经过P点的入射光线没有透镜的话,本应交于相机成像平面的e点。然而,经过鱼眼相机的折射,光线会交于相机成像平面的d点,就产生了畸变,因此畸变图像整体上呈现出像素朝图像中心点聚集的态势。
去畸变,就是将折射到d点的点,重新映射回到e点,因此去畸变之后的图像与原始的鱼眼图像相比,仿佛是把向心聚集的像素又重新向四周铺展开来。下表中的两幅图分别为鱼眼图和去畸变之后的展开图:
鱼眼相机的投影方式有很多种假设,例如等距投影、等立体角投影、正交投影、体视投影、线性投影。但是真实的鱼眼相机镜头并不完全遵循上述的这些模型假设。因此Kannala-Brandt提出了一种一般形式的估计,适用于不同类型的鱼眼相机:
这个也是纳入opencv中的鱼眼相机畸变模型。现在基本上默认鱼眼相机模型遵循上述公式。公式中的θ为光线入射角,r(θ)为上图中od的长度。
SLAM
SLAM (Simultaneous Localization And Mapping,同步定位与地图构建),主要为了解决移动机器人在未知环境运行时定位导航与地图构建的问题。SLAM根据不同的传感器类型和应用需求建立不同的地图。常见的有 2D 栅格地图、2D 拓扑地图、3D 点云地图等。VSLAM(Visual SLAM)一种基于视觉的同步定位与地图构建。
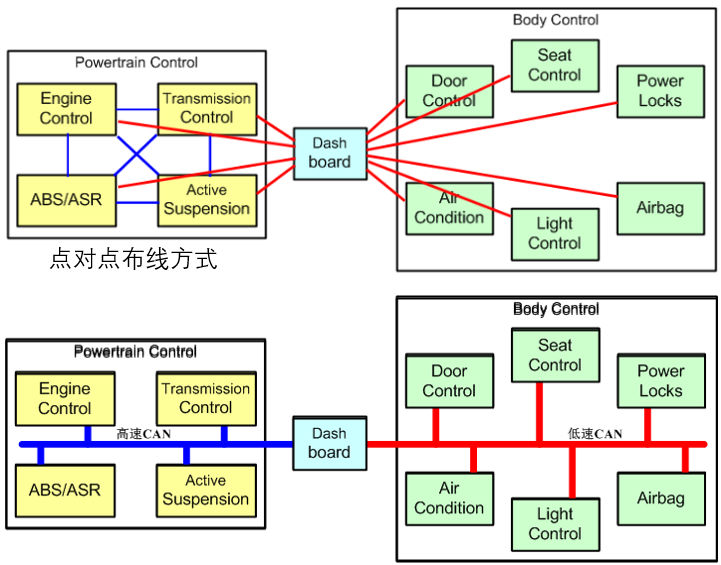
车载测试[2]:
学术上,严谨的“闭环”概念是在控制论中出现的。较为抽象的定义是:当我们要准确控制一个系统的行为时,我们根据系统的输出来校正对它的输入,以达到较为准确的控制精度。因为系统的输出会导入到输入端的计算,形成一个不断往复的循环,称之为闭环(Closed Loop)。
- MIL(Hardware-in-the-Loop模型在环):主要用于在模拟环境中评估控制算法的功能性,确认模型是否能实现设计的需求。这通常在早期开发阶段进行,有助于及早发现设计问题。
- SIL(Software-in-the-Loop软件在环):在PC上验证代码实现的功能是否与模型一致。
- PIL(Processer-in-the-Loop处理器在环):在目标处理器上验证代码实现的功能是否与模型一致。
- HIL(Hardware-in-the-Loop硬件在环):在ECU/EPP/整套系统上验证代码实现的功能是否与需求定义一致。
![picture 1]()

数据
numpy
有些数据集会用更高效的npz格式存取:
NumPy:tofile、fromfile、load 和 save。将NumPy数组存储到文件中,以及从文件中加载数组。
- tofile
tofile 函数将数组的内容写入到二进制文件中。它不保存数组的形状或数据类型,只是将数据以二进制格式存储。1
2
3
4
5import numpy as np
# 创建一个示例数组
array = np.array([1, 2, 3, 4, 5])
# 将数组写入到文件中
array.tofile('array.bin') - fromfile
fromfile 函数从二进制文件中读取数据并将其转换为NumPy数组。它需要指定数据类型和形状,以便正确解析文件中的数据。1
2
3# 从二进制文件中读取数据
array = np.fromfile('array.bin', dtype=np.int64) # 确保 dtype 和文件内容一致
print(array) - save
save 函数将NumPy数组保存为 .npy 格式的文件,这种格式会保存数组的形状、数据类型等元数据。1
2
3
4# 创建一个示例数组
array = np.array([1, 2, 3, 4, 5])
# 将数组保存到 .npy 文件
np.save('array.npy', array) - load
load 函数从 .npy 文件中加载数组,恢复保存时的形状和数据类型。
import numpy as npsave 和 load 使用 NumPy 的 .npy 格式,保存和加载时会包括数组的形状和数据类型信息。1
2
3
4# 从 .npy 文件中加载数组
array = np.load('array.npy')
print(array)
tofile 和 fromfile 用于处理二进制数据文件,通常不保存数组的元数据(形状和数据类型)。
如果需要保存元数据并且确保数据的完整性,使用 .npy 格式是更好的选择;如果只是处理原始数据,使用二进制格式可能会更高效。
数据类型
常用到的图片数据类型包括rgb、bgr、gray、yuv444、nv12、featuremap。
数据输入格式 rgb/bgr/gray/featuremap/yuv444
RGB: 将颜色分为红色(R)、绿色(G)、蓝色(B)三个通道。(0-1)(UINT8)
RGB 图像中,每个像素点都有红、绿、蓝三个基底颜色,以不同的比例相加,可以产生多种多样的颜色,其中每种原色都占用 8 bit,也就是一个字节(0-255),那么一个像素点也就占用三个字节。在图像显示中,一张 1280 * 720 大小的图片,其中每一个像素点的颜色显示都采用 RGB 编码方法,将 RGB 分别取不同的值,就会展示不同的颜色,就占用 1280 * 720 * 3 / 1024 / 1024 = 2.63 MB 存储空间。
BGR: BGR与RGB类似,区别在于通道顺序不同,分别表示蓝色(B)、绿色(G)、红色(R)。OpenCV等库中常用BGR格式表示图像数据,例如图像处理和计算机视觉任务中的输入图像。(0-255)(UINT8)
YUV: YUV 颜色编码采用的是 明亮度 和 色度 来指定像素的颜色。Y表示明亮度(Luminance、Luma) U 和 V 表示色度(Chrominance、Chroma)而色度又定义了颜色的两个方面:色调和饱和度。这样分开的好处就是不但可以避免相互干扰,还可以降低色度的采样率而不会对图像质量影响太大
- YUV444: 每一个Y对应一组UV分量。每个通道的采样率都是1:1。在视频编解码或者实时视频处理中,YUV444格式用于保留更多的色彩信息。若只保留Y分量,则是灰度图,灰度图像常用于简化计算或者提取图像中的亮度信息,如人脸识别中的预处理步骤。(UINT8)
和rgb一样每个像素点占用3个字节 (UINT8)
- YUV422:每两个Y共用一组UV分量。Y 分量和交替的 U 和 V 分量,通常用于更高的色彩保真度。根据存储顺序不同又分为YUVY, YUYV,UYVY等等
一张 1280 * 720 大小的图片,在 YUV 4:2:2 采样时的大小为:
(1280 * 720 * 8 + 1280 * 720 * 0.5 * 8 * 2)/ 8 / 1024 / 1024 = 1.76 MB - YUV420:每四个Y共用一组UV分量。Y 分量通常是原始灰度数据,U 和 V 分量是下采样后的色彩数据。
0并不是指只采样 U 分量而不采样 V 分量。而是在每一行扫描时,只扫描一种色度分量(U 或者 V),和 Y 分量按照 2 : 1 的方式采样。比如,第一行扫描时,YU 按照 2 : 1 的方式采样,第二行扫描时,YV 分量按照 2:1 的方式采样。对于每个色度分量来说,它的水平方向和竖直方向的采样和 Y 分量相比都是 2:1 。- NV12 和 NV21 格式都属于 YUV420 类型。其中NV12是先存 Y 分量,再 UV 进行交替存储,NV21是先存 Y 分量,在 VU 交替存储。
一张 1280 * 720 大小的图片,在 YUV 4:2:0 采样时的大小为:(1280 * 720 * 8 + 1280 * 720 * 0.25 * 8 * 2)/ 8 / 1024 / 1024 = 1.32 MB,可以看到 YUV 4:2:0 采样的图像比 RGB 模型图像节省了一半的存储空间,因此它也是比较主流的采样方式。
- NV12 和 NV21 格式都属于 YUV420 类型。其中NV12是先存 Y 分量,再 UV 进行交替存储,NV21是先存 Y 分量,在 VU 交替存储。
![alt text]()
- YUV444: 每一个Y对应一组UV分量。每个通道的采样率都是1:1。在视频编解码或者实时视频处理中,YUV444格式用于保留更多的色彩信息。若只保留Y分量,则是灰度图,灰度图像常用于简化计算或者提取图像中的亮度信息,如人脸识别中的预处理步骤。(UINT8)

( R, G, B ) 的范围是 [0, 255],(Y)通常在[0, 255]之间,而(U, V)一般在[-128, 127]之间。
[
\begin{align*}
Y & = 0.299R + 0.587G + 0.114B \
U & = -0.14713R - 0.28886G + 0.436B \
V & = 0.615R - 0.51499G - 0.10001B
\end{align*}
]
[
\begin{align*}
R & = Y + 1.13983V \
G & = Y - 0.39465U - 0.58060V \
B & = Y + 2.03211U
\end{align*}
]
- Feature Map: 特征图是深度学习网络中间层的输出,通常是各种滤波器对输入图像的响应。它们是网络中特征提取的结果。在卷积神经网络(CNN)中,每个卷积层都会输出多个特征图,代表不同的特征,如边缘、纹理等。(float32)
张量:也称Tensor,具备统一数据类型的多维数组,作为算子计算数据的容器,包含输入输出数据。 张量具体信息的载体,包含张量数据的名称、shape、数据排布、数据类型等内容。
数据排布:深度学习中,多维数据通过多维数组(张量)进行存储,通用的神经网络特征图通常使用四维数组(即4D)格式进行保存,即以下四个维度:
N:Batch数量,如图片的数量。
H:Height,图片的高度。
W:Width,图片的宽度。
C:Channel,图片的通道数。
但是数据只能线性存储,因此四个维度有对应的顺序,不同的数据排布(format)方式,会显著影响计算性能。 常见的数据存储格式有NCHW和NHWC两种,是流行的深度学习框架不同的数据格式[1]:
NCHW:将同一通道的所有像素值按顺序进行存储。
NHWC:将不同通道的同一位置的像素值按顺序进行存储。
Note
FOV(Field of View,视场角)
BEV感知
在自动驾驶领域,BEV 是指从车辆上方俯瞰的场景视图。BEV 图像可以提供车辆周围环境的完整视图,包括车辆前方、后方、两侧和顶部。
BEV 图像可以通过多种方式生成,包括:
- 使用激光雷达:激光雷达可以直接测量物体在三维空间中的位置,然后将这些数据转换为 BEV 图像。
- 使用摄像头:摄像头可以通过计算图像的透视投影来生成 BEV 图像。
- 使用混合传感器:可以使用激光雷达和摄像头的组合来生成 BEV 图像,以获得更精确和完整的视图。
在纯视觉方案中又分为传统方法和深度学习方法
- 传统方法:IPM(Inverse Perspective Mapping,逆透视变换)
通过多相机的内外参标定,求得相机平面到地平面的单应性矩阵,实现平面到平面的转换,再进行多视角图像的拼接。
局限性:
- 依赖标定的准确性,且内外参必须固定。
- 假设地面平坦、目标接地,难以应用在较远距离的感知任务中。
- 深度学习方法:
LSS(Lift-Splat-Shoot)
Lift(2D → 3D 视锥点云)
- 深度估计、特征提取。
- 不是直接回归深度值,而是对每个像素点预测一系列离散深度值的概率,得到深度分布特征 α 和图像特征 c。
- 将两者做外积,得到视锥特征(frustum-shaped point cloud)。
Splat(3D → BEV 视角)
- 透视变换、体素池化(Voxel Pooling)。
- 通过相机内外参,将3D点云转换到自车坐标系(Ego 坐标系)。
- 体素池化(Voxel Pooling)
- 点云是稀疏的、不规则的,但 BEV 感知任务通常使用规则化的网格(体素网格)进行计算。
- 体素(Voxel,Volume Pixel)是三维空间中的像素单位,类似于二维图像中的像素(Pixel),存在高度信息的像素, 用于表示 3D 体积数据。具有无限高度的 voxel 称为 pillar。
- 体素池化:通过 Splat(投影) 操作,将 3D 视锥点云投影到 BEV 网格中的过程:每个视锥的每个点分配给最近的 pillar,再执行 sum pooling,得到 CxHxW 的 BEV 特征。对于落入同一个 BEV 网格的多个点,使用池化操作(sum-pooling 或 max-pooling)进行特征融合,生成 BEV 视角的特征图。
Shoot(BEV 视角下的计算)
- 特征融合、目标检测。
- 在 BEV 视角下进行目标检测、语义分割、路径规划等任务。